Segmentation-based Baseline
Segmentation-based approach do not scale well to all terrains seen in the real world, and need additional human annotations to be collected for each new terrain.

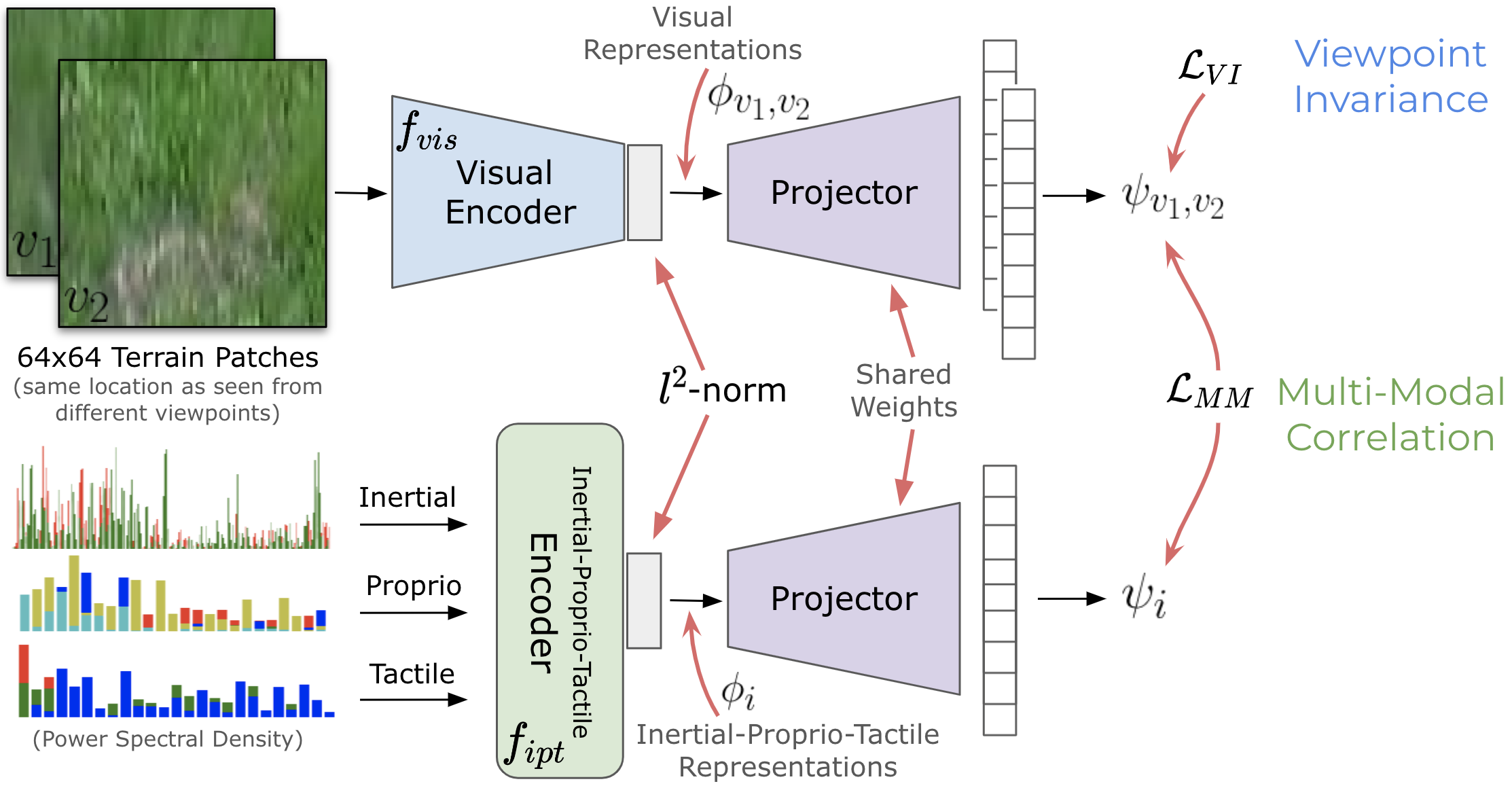
Segmentation-based approach do not scale well to all terrains seen in the real world, and need additional human annotations to be collected for each new terrain.
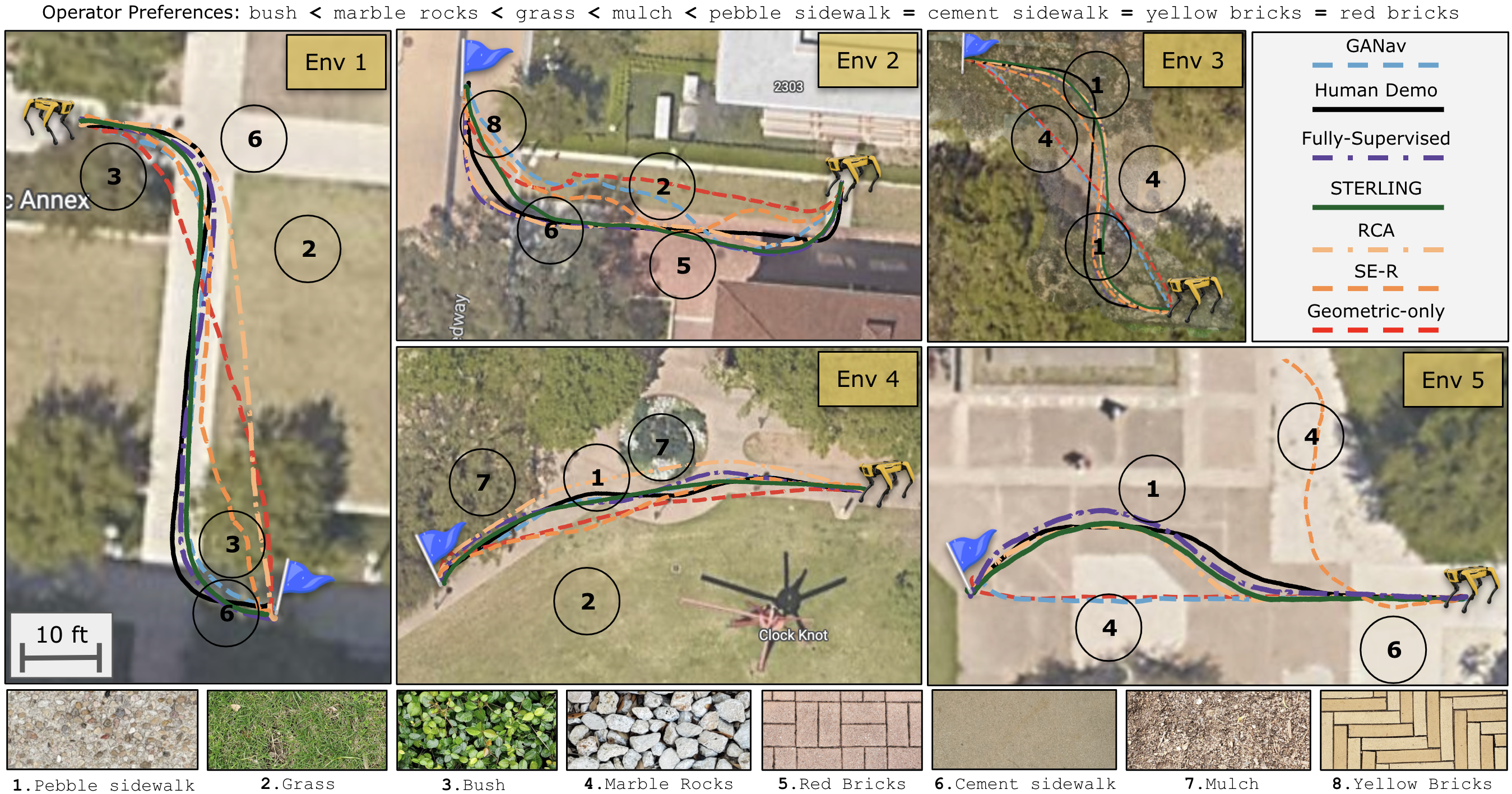
STERLING learns representations in a self-supervised manner and hence can easily adapt to terrains in the real world, enabling preference-aligned navigation.
Also checkout our recent work, available as a pre-print (PATERN) on extrapolating operator preferences to visually novel terrains.
This work has taken place in the Learning Agents Research Group (LARG) and Autonomous Mobile Robotics Laboratory (AMRL) at UT Austin. LARG research is supported in part by NSF (CPS-1739964, IIS-1724157, NRI-1925082), ONR (N00014-18-2243), FLI (RFP2-000), ARO (W911NF19-2-0333), DARPA, Lockheed Martin, GM, and Bosch. AMRL research is supported in part by NSF (CAREER2046955, IIS-1954778, SHF-2006404), ARO (W911NF-19-2- 0333, W911NF-21-20217), DARPA (HR001120C0031), Amazon, JP Morgan, and Northrop Grumman Mission Systems. Peter Stone serves as the Executive Director of Sony AI America and receives financial compensation for this work. The terms of this arrangement have been reviewed and approved by the University of Texas at Austin in accordance with its policy on objectivity in research.
@inproceedings{karnan2023sterling,
title={STERLING: Self-Supervised Terrain Representation Learning from Unconstrained Robot Experience},
author={Haresh Karnan and Elvin Yang and Daniel Farkash and Garrett Warnell and Joydeep Biswas and Peter Stone},
year={2023},
booktitle={7th Annual Conference on Robot Learning},
url={https://openreview.net/forum?id=VLihM67Wdi6}
}